Introduction
An in-depth guide exploring what an AI Agent is, why it matters, how the automation lifecycle works, and a practical roadmap to get from idea to production — fast.
The question is simple but consequential: “Should we use AI agents?”
The follow-up is urgent: “How fast can we start?”
Across industries, organizations are wrestling with these questions. An AI Agent — a software entity that perceives, reasons, acts, and learns — promises to automate repetitive work, augment human expertise, and scale decision-making. But adopting AI agents is not just a technology choice; it’s a product strategy, an operational shift, and a governance challenge.
This article walks you through the whole picture: what an AI Agent is, the five-stage automation lifecycle (Data Collection → Processing → Decision-Making → Execution → Learning & Feedback), concrete examples, supporting software, a realistic implementation roadmap, governance and risk controls, KPIs, and a practical timeline so you can answer the second question with confidence: how fast can we start?
What is an AI Agent?
An AI Agent is a software component that combines sensing, reasoning, and action-taking capabilities to achieve goals autonomously or semi-autonomously. Unlike static scripts or rule-based automation, modern AI agents can:
- Interpret unstructured inputs (text, speech, images).
- Reason under uncertainty using statistical models or heuristics.
- Adapt over time through learning and feedback.
- Coordinate with other agents or human teams to complete complex tasks.
Types of AI agents vary by capability and complexity:
- Rule-based agents: follow explicit business rules (simple automation).
- Retrieval + reasoning agents: search knowledge stores and synthesize responses (e.g., customer support assistants).
- Planning agents: create multi-step plans to reach a goal (e.g., scheduling across calendars).
- Learning agents: incorporate machine learning to improve decisions (e.g., fraud detection models).
- Multi-agent systems: multiple agents collaborate — each with specialized roles (e.g., orchestration agent, data agent, action agent).
Why this matters: The word “agent” signals autonomy and goal-driven behavior. An AI Agent should reduce manual work while maintaining traceability, safety, and measurable value.
Why Use AI Agents? The Strategic Rationale
Before building anything, answer the strategic question: what outcomes do we want? Organizations adopt AI agents for five main reasons:
- Cost and Time Savings
AI agents automate repetitive, predictable tasks—scheduling, triage, reporting—freeing valuable human time. - Operational Scalability
Agents scale horizontally: once trained and integrated, an agent can handle thousands of concurrent workflows without proportional headcount increases. - Consistency and Accuracy
Well-designed agents deliver consistent outputs (e.g., code of conduct applied uniformly, diagnosis suggestions based on the same evidence). - Speed of Decisioning
Real-time monitoring agents can detect anomalies and trigger actions faster than humans—critical in areas like healthcare monitoring or fraud prevention. - Continuous Improvement
Learning-capable agents can improve performance over time, discovering patterns humans miss.
When NOT to use AI agents: If a task requires deep human empathy, legal judgment, or involves extremely rare, novel scenarios with no historical data, full automation may be premature. Instead, design human-in-the-loop systems.
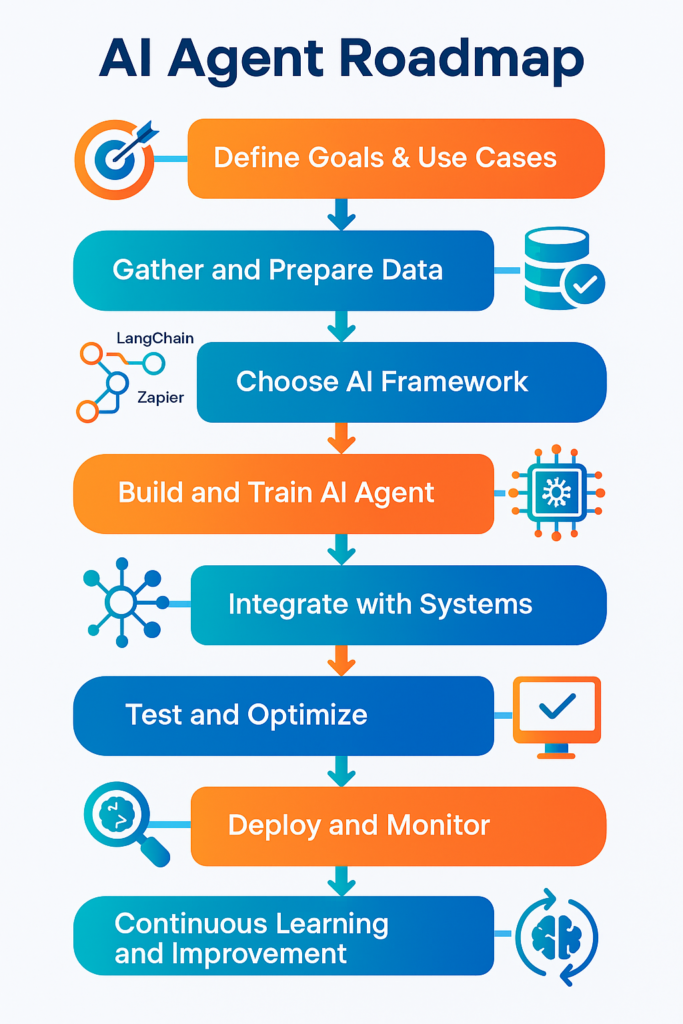
The 5 Key Stages of an AI Agent Automation Workflow — Detailed Explanation
Successful AI agent projects follow a lifecycle. Below we unpack each stage, practical considerations, common pitfalls, and examples.
1. Data Collection (Inputs: raw fuel for the agent)
What it is: Gathering structured and unstructured data the AI agent will need: sensor feeds, application logs, EHR records, images, chat transcripts, API responses, etc.
Why it matters: The agent’s decisions are only as good as the data it sees. Poor quality or biased data produces unreliable agents.
Key activities:
- Inventory data sources: List internal systems, external APIs, IoT sensors, datastores.
- Establish connectors: Build robust, authenticated integrations (webhooks, API clients, message queues).
- Define data contracts: Standardize formats, units, schemas, and SLAs for update frequency.
- Implement ingestion pipelines: Stream or batch pipelines (Kafka, Kinesis, cloud pub/sub) with reliable delivery.
- Ensure provenance & lineage: Capture where the data came from and transformations applied.
Quality controls:
- Validate schemas at ingest time.
- Implement deduplication and timestamps.
- Monitor missing fields and drift.
Example: Healthcare AI Agent
- Sources: patient vitals from bedside monitors (stream), EHR medications (API), imaging (DICOM), nurse notes (unstructured text).
- The data collection layer ensures the AI Agent has synchronized, time-stamped records for each patient.
Pitfalls to avoid:
- Relying on a single fragile API.
- Ignoring latency needs — some agents need real-time streams, others are fine with hourly batches.
- Forgetting privacy constraints — personal health data requires strict controls.
2. Processing (Transforming raw data into signals)
What it is: Cleaning, enriching, normalizing, and converting raw inputs into features or structured signals the agent can reason about.
Why it matters: Raw data is noisy. Processing turns it into reliable features and embeddings that models and rules can use.
Key activities:
- Data cleaning: Null handling, outlier detection, unit normalization.
- Feature engineering: Construct features (rolling averages, categorical encodings, embeddings).
- Contextual enrichment: Link disparate records (e.g., join vitals with medication records).
- Indexing and retrieval: Build vector databases or search indices for retrieval-based agents (Haystack, FAISS, Weaviate).
- Batch vs. stream processing: Choose frameworks (Spark, Flink, Beam) based on throughput and latency.
Tools & techniques:
- ETL/ELT frameworks: dbt, Airflow for pipelines.
- Feature stores: Feast, Tecton for reuse and consistency.
- Vector DBs for semantic search: Weaviate, Pinecone, Milvus.
Example: Customer Support Agent
- Convert ticket text to embeddings.
- Extract customer metadata.
- Index past resolved tickets for retrieval.
Pitfalls to avoid:
- Overfitting to engineered features without validating generalization.
- Not versioning features — makes reproducibility hard.
3. Decision-Making (The agent’s “brain”)
What it is: Selecting actions based on processed data using rules, ML models, or a combination (hybrid reasoning).
Why it matters: A well-designed decision layer chooses appropriate actions, handles uncertainty, and escalates when needed.
Decision paradigms:
- Rule-based: If-then logic for deterministic tasks (e.g., if lab value > X, flag).
- Probabilistic: Outputs with confidence scores (e.g., risk = 0.87, then notify).
- Optimization/Planning: Create multi-step plans (e.g., reschedule appointments across providers).
- Reinforcement learning: Learn policies from reward signals (used in complex control tasks).
- LLM-based reasoning: Use language models to synthesize and reason over data (with tool use patterns).
Design patterns:
- Hybrid approach: Combine deterministic rules for safety-critical checks and ML for probabilistic recommendations.
- Thresholds and confidence gating: Only auto-act when confidence > threshold; otherwise route to a human.
- Explainability hooks: Record why a decision was made for audit and debugging.
Example: Financial Fraud Agent
- Use a trained classifier to score transactions.
- If score > 0.95 → block transaction automatically.
- If 0.6 < score < 0.95 → flag for human review and show explainability attributes (which features pushed the score).
Pitfalls to avoid:
- Letting ML models act with no safety net.
- Ignoring the calibration of confidence scores.
4. Execution (Carrying out actions in the world)
What it is: The agent acts — sending messages, updating records, triggering workflows, calling APIs, or even operating devices.
Why it matters: Execution is where business value is realized. It must be reliable, idempotent, and auditable.
Execution modes:
- Automated actions: Directly perform tasks (book appointment, block transaction).
- Advisory mode: Provide suggestions for humans to accept.
- Hybrid: Auto-complete low-risk tasks, escalate high-risk ones.
Key requirements:
- Idempotency: Avoid duplicate side effects on retries.
- Transactional guarantees: Use sagas or distributed transactions where needed.
- Retry & backoff: Resilient to transient failures.
- Observability: Log actions, responses, and latencies.
- Human-in-the-loop UX: Clear interfaces for review and override.
Example: Hospital Admin Agent
- Execution: Reschedule appointments via provider calendar API, send SMS confirmations via messaging gateway.
- Safety: If double-booking detected, route to admin team for confirmation.
Pitfalls to avoid:
- Blindly executing destructive actions (e.g., deleting records) without proper checks.
- Forgetting permission boundaries — the agent should have scoped credentials.
5. Learning & Feedback (Continuous improvement loop)
What it is: Monitor results, collect labels or feedback, and retrain or tune the agent to improve accuracy and value.
Why it matters: Static agents degrade over time as data and context shift; learning keeps the agent effective.
Feedback sources:
- Explicit human feedback: Approvals, corrections, ratings.
- Implicit signals: Task completion, user engagement, conversion rates.
- Ground truth events: Chargebacks for fraud; readmissions in healthcare.
Processes to implement:
- Label collection: Build simple UIs that capture why humans adjusted agent decisions.
- Drift detection: Monitor feature distributions and model performance.
- A/B testing & shadow policies: Test improvements in safe deployments.
- Retraining pipelines: Automate scheduled or trigger-based retraining with validation gates.
Governance:
- Maintain model registries and versioning.
- Keep a rollback plan and defined SLA for retraining frequency.
Example: Customer Recommendation Agent
- Track click-through and purchase as feedback.
- Retrain models weekly using new interaction data and evaluate lift.
Pitfalls to avoid:
- Retraining on biased or poisoned labels.
- Retraining too frequently without validations, causing instability.
Concrete Examples of AI Agents (Realistic, practical)
- Admin Scheduling Agent (Healthcare)
- Role: read provider calendars, patient preferences, and insurance constraints to auto-schedule appointments.
- How it works: Agent queries calendar APIs, scores slots via a planning algorithm, and executes booking after consent.
- Value: Reduces admin time, increases utilization, and improves patient satisfaction.
- Monitoring & Alerting Agent (Operations)
- Role: watch telemetry (CPU, memory, logs) and recommend or execute scaling actions.
- How it works: Streams telemetry to a model that predicts incidents; triggers an auto-remediation playbook for common failures.
- Value: Faster MTTR, fewer outages.
- Triage Agent (Customer Support)
- Role: classify incoming tickets, suggest answers, and route to specialist teams.
- How it works: NLP model classifies intent, the retrieval agent fetches past answers, and the workflow agent routes high-priority items to humans.
- Value: Faster response times, better SLA adherence.
- Predictive Maintenance Agent (Manufacturing)
- Role: analyze sensor data to predict equipment failure and schedule maintenance.
- How it works: Time-series models detect anomaly patterns; the agent opens maintenance tickets automatically.
- Value: Reduced downtime and repair costs.
- Fraud Detection Agent (Finance)
- Role: detect suspicious transactions in real-time and hold or flag them.
- How it works: Ensemble models score events; if borderline, the agent initiates a multi-step verification workflow.
- Value: Lower losses, improved trust.
How Fast Can We Start? — Practical Timelines and Approaches
Speed depends on scope, data readiness, and risk appetite. Below are three typical approaches and realistic timelines.
1. Lightning Start — Minimal Viable Agent (Days → 2 weeks)
Scope: Automate a single, well-defined administrative task (e.g., send appointment reminders or summarize incoming emails).
Why it’s fast:
- Uses off-the-shelf APIs (LLM or transcription) and low-code automation (Zapier, n8n).
- No heavy model training; mostly integration and rule design.
Typical steps & time:
- Day 0–1: Define the use case and success metrics.
- Day 1–3: Connect data sources and messaging channels.
- Day 3–7: Wire LLM or rule-based logic and test flows.
- Day 7–14: Pilot with limited users and iterate.
Risks: Limited to low-risk tasks. Avoid high-sensitivity or safety-critical automation.
2. Pragmatic Pilot — Production-Ready Agent (4–12 weeks)
Scope: A robust agent that integrates with core systems, has logging, and limited automation of non-critical decisions.
Typical steps & time:
- Week 1–2: Use-case definition, data mapping, compliance checks.
- Week 2–4: Build ingestion and processing pipelines.
- Week 4–6: Implement decision models and business rules.
- Week 6–8: Build execution layer and human-in-the-loop interface.
- Week 8–12: Run a controlled pilot, evaluate KPIs, and refine.
Value: Get measurable ROI while protecting against risk with gating and review.
3. Enterprise Rollout — Multi-Agent System (3–9 months)
Scope: Large-scale integration across multiple systems, with ML training, high reliability, and complex workflows.
Typical steps:
- Proof-of-concept and stakeholder alignment (1 month).
- Data engineering & feature store setup (1–2 months).
- Model development and validation (1–2 months).
- Integration, security audits, and compliance (1–2 months).
- Staged rollout and retraining pipelines (ongoing).
Notes: Requires cross-functional teams, strong governance, and budget for infrastructure.
Supporting Software & Frameworks (What to use)
Below are categories and example tools you can use to build AI Agents. Choose based on your team’s expertise, performance needs, and constraints.
AI Model & Reasoning
- OpenAI (GPT family) / Anthropic (Claude) — natural language understanding, planning, and tool use.
- Hugging Face Transformers — open models for custom deployments.
- Rasa / Dialogflow — conversational agents with state management.
Agent Frameworks & Orchestration
- LangChain — design patterns for building LLM-powered agents, chains, and tool integrations.
- AutoGen / Microsoft Bot Framework — multi-agent coordination and orchestration.
- CrewAI — multi-agent orchestration (emerging tools).
Automation & Integration
- Zapier / Make / n8n — no-code/low-code connectors for rapid prototypes.
- Apache Airflow — scheduled workflow orchestration for data pipelines.
- Temporal — durable workflows and orchestration with strong retry semantics.
Data Infrastructure
- Kafka / Kinesis — event streaming.
- Feast / Tecton — feature stores.
- Pinecone / Weaviate / Milvus — vector databases for semantic retrieval.
Monitoring & MLOps
- Prometheus / Grafana — metrics and dashboards.
- Seldon / BentoML / MLflow — model serving and lifecycle.
- Evidence / WhyLabs — data/model drift monitoring.
Security & Privacy
- Vault for secrets management, KMS for key management.
- Data masking and differential privacy libraries where relevant.
Implementation Roadmap — Step-by-Step (Practical)
Here is a repeatable 8-week roadmap for a pragmatic pilot AI Agent that balances speed with production readiness.
Week 0: Discovery & Alignment
- Stakeholders workshop: define objectives, KPIs, and acceptance criteria.
- Select a single high-impact use case (low risk but high ROI).
- Identify data sources and regulatory constraints.
Week 1–2: Data & Integration
- Build connectors to required systems (APIs, databases).
- Implement initial data validation and storage.
- Create monitoring for data freshness and quality.
Week 3–4: Model & Logic
- Decide model approach (LLM, classifier, rules).
- Implement processing pipelines and a prototype decision module.
- Design human-in-the-loop flows and explainability artifacts.
Week 5: Execution & Safety
- Implement execution layer with idempotency, retries, and scoped credentials.
- Create audit logging and role-based access to actions.
- Build rollback procedures.
Week 6: Pilot & Observability
- Deploy to a small user base or shadow mode.
- Monitor performance, error rates, and user feedback.
- Collect labels and build an initial retraining dataset.
Week 7–8: Iterate & Harden
- Incorporate feedback, fix edge cases.
- Tune thresholds and add circuit breakers.
- Document runbooks and training materials.
Post-Pilot: Scale & Govern
- Plan a phased rollout.
- Establish MLOps and monitoring schedules.
- Define long-term governance (ethical review board, compliance checks).
Governance, Ethics, and Risk Management
Deploying AI agents without governance is risky. Here’s a compact governance framework:
- Risk Assessment
- Categorize use cases by impact (low/medium/high).
- For high-impact use cases (healthcare decisions, financial holds), require human review.
- Privacy & Compliance
- Map data flows and ensure lawful bases for processing.
- Apply encryption, access controls, and data minimization.
- Bias & Fairness Checks
- Test models for disparate impacts.
- Use counterfactual and subgroup analysis.
- Explainability & Auditability
- Log decision inputs, reasoning traces, and final actions.
- Provide human-readable explanations for automated decisions.
- Operational Controls
- Rate limits, rollback procedures, and alerting for anomalies.
- Regular audits of training data, retraining schedules, and performance.
- Human Oversight
- Keep humans “in the loop” for uncertain or high-risk actions.
- Build clear UIs that allow quick overrides and capture feedback.
Measuring Success — KPIs & Metrics
Pick KPIs tied to business outcomes:
- Accuracy / Precision / Recall (for classification agents).
- Automation Rate: percentage of tasks fully automated vs. routed to humans.
- Time Saved: reduction in average handling time (AHT).
- Cost Per Transaction: pre vs. post-agent.
- Error Rate / False Positive Rate: critical where mistakes are costly.
- Human Satisfaction / Trust Scores: survey results from users and customers.
- Retraining Improvement: lift in metrics after each retraining.
Set target thresholds for go/no-go decisions and continuously measure.
Example Project — Mini Case Study (Hypothetical but realistic)
Company: MedFlow, a mid-size outpatient network
Problem: Scheduling bottlenecks, missed appointments, and administrative overload.
Solution: Deploy a multi-agent system:
- Intake Agent: Parses appointment requests and checks eligibility.
- Scheduling Agent: coordinates calendars across providers and suggests optimal slots.
- Reminder Agent: sends confirmations and handles rescheduling.
- Escalation Agent: routes conflicts to human schedulers.
Outcome after 3 months:
- Missed appointments down 40%.
- Administrative hours saved per week: 120.
- Patient satisfaction scores improved by 12 points.
Why it worked: Clear scope, solid data integrations, safety checks around double-booking, and human oversight for complex cases.
FAQs (Practical Questions You’ll Ask)
Q: Will AI Agents take jobs?
A: They change job composition. Routine tasks are automated, freeing humans for higher-value work. Planning for reskilling is critical.
Q: How much does it cost to build an AI Agent?
A: Minimal pilots can be low-cost (a few thousand USD) using cloud APIs and no-code tools. Enterprise rollouts involve infrastructure, data engineering, and compliance — tens to hundreds of thousands depending on scale.
Q: Can I build an AI Agent without an ML team?
A: Yes. Start with rule-based and LLM-powered agents using off-the-shelf APIs and low-code platforms. As complexity grows, bring in data engineering and ML expertise.
Q: How do we ensure safety?
A: Use confidence thresholds, human review gates, logging, and tests (unit, integration, and chaos testing).
Final Thoughts — Should We Use AI Agents? How Fast Can We Start?
If your organization faces repetitive processes, high-volume decisions, or opportunities to scale expertise, AI Agents are worth exploring. They deliver measurable value quickly when scoped correctly and governed responsibly.
How fast can you start?
- For low-risk admin automation: days to a couple of weeks.
- For production-ready agents with integrations: 4–12 weeks.
- For enterprise multi-agent systems: 3–9 months from discovery to full rollout.
A practical recommendation: pick a single high-impact, low-risk use case. Build a Minimal Viable Agent in weeks using existing APIs and automation tools. Measure results, collect feedback, and scale — iterating with stronger governance and MLOps as you grow.